In the previous two parts of the Cloud Strategy blog we discussed the organizational changes required to adopt a cloud operating model and different phases of migration. In this part, let’s first look at a real customer scenario where Hybrid Cloud is a great fit and then explore some generic use cases.
Customer Case Study: E-commerce application that needed to rapidly innovate to provide business intelligence
Biz Requirement: A major, legacy e-commerce retailer needs to stay competitive (against disruptive newcomers like StitchFix etc.), retain customers and increase revenue from online and in-store shoppers.
Technology Requirement: To stay relevant, the e-commerce portal needs to be able to collect analytics from visitors to their site, use algorithms and data science to personalize clothing items based on size, budget, local trends and style.
Constraints: Moving the existing 3 tier app to a native public cloud provider is deemed too risky and expensive and is not an option. This project needs to be completed in a very short timeline. Application cannot be refactored and the guidance is to make as few changes as possible to the stable working environment.
Assumptions: Sufficient in-house public cloud and DB/Business intelligence technology experience is available. Any changes will not impact the core framework and will be performed with rigorous testing and in a manner that introduces least amount of risk. Operational teams are skilled and agile to adapt to new solutions and technology stacks and can provide guardrails around security in public cloud.
Risks: Introducing changes to any existing application, inherently introduces risks. Adopting new solutions, can expose security and operational gaps.
Current Architecture and Proposed Enhancements:
The current application was a 3-tier application deployed on-premises. It consisted of VM’s and an SQL database for storing transactions. Developers wanted to use a secondary database for Online analytics processing (OLAP). They needed a NoSQL database to support click-stream captures and gather intelligence about site visitors, their browsing history and preferences. The developers were unsure of which NoSQL DB would be a right choice for them. The analyzed what the intended use would be and how big it would grow. But this data was not definitive until they were able to deploy and analyze the data that they would actually be able to collect.
One group wanted to go with either CouchDB or MongoDB and use a document based, JSON compatible database. Another group was sure that they would be collecting lot of data and wanted to start with a large columnar DB- like Cassandra DB or a managed NoSQL db like DyanmoDB.
From an IT perspective, supporting each of these requests takes months of preparation – right from sourcing vendors, identifying compute resources, security framework, operational models, training and education etc. These workloads are better suited to be supported on public cloud.
The cost to allow developers to experiment on public cloud is minimal compared to supporting both DB options in house. Developers are allowed the freedom to explore the public cloud’s virtually unlimited cloud eco-system choices, do some rapid prototyping and fail fast. This allows them to make an informed choice.
We designed this high-level hybrid cloud architecture to allow developers the fastest path to innovate without rewriting their entire application in public cloud or having to lift and shift.

The block architecture is kept intentionally simple but demonstrates an easy approach to add “hybridity” to any application that is running in a traditional data center.
Developers added some web-hooks to capture click-stream data in parallel. This data was exported to a noSQL DB like DyanmoDb on AWS. This export was made over a secure VPN connection over Direct Connect. API Gateways are also a good way to import or export data into public cloud. Once this data was in a noSQL DB on a public cloud, it was very easy to allow developers their choice of tools to analyze it. A simple Lambda workflow was proposed to break this new data into ingest-able chunks and a Kinesis work stream was suggested to convert this data into business intelligence.
The last part of this was to provide this data back to the business to make personalized recommendations, promo codes and other incentives to the shopper to complete a transaction.
Still not convinced on what business intelligence/data analytics can provide? See how Netflix suggest different titlecards for the same shows based on user preferences.
VMConAWS and Other hosted VMware Engines
This “on-premises” 3-tier application could just as easily be migrated to VMware Cloud on AWS or other Hyper-scale cloud solutions like Google VMware Engine or Azure VMware Solutions to reduce latency and to provide better access to the cloud-ecosystem. In the case of VMConAWS, there are no egress charges between a VMware SDDC (which would typically host the 3-tier app in AWS) and services used from a native AWS VPC, within the same region. This blog provides a good description of the egress charges.
The migration is greatly simplified because of the ability to maintain the same operational experience and tools that the operations teams are already used to, to support a VMware stack in a public cloud.
Note- in this case above, latency is not an issue as the transactional DB was still on-premises and the business did not need sub second granularity for the business analytics input.
Hybrid Cloud especially makes sense for these workloads:
- Legacy apps that are still business critical but are stable and have predictable resource requirements. In some cases, the supporting products are already End of Life, with extended support options.
- Applications where it doesn’t make sense to lift and shift to public cloud, there may be ongoing multi-year efforts to re-architect them.
- Dev or Production workloads with supporting services that IT is comfortable supporting on-premises -i.e. no developer/experimental projects that require cutting edge technology stack. The eco-system of supporting services has a mature, enterprise grade support available or SaaS options which can offload in house IT expertise required. For instance, it is straightforward for IT to support SQL Server 2019 as opposed to an on-premise NoSQL solution. In public cloud there are plethora of options.
- Compliance requirements that limit applications and their data to be stored in public cloud. While public cloud is inherently secure and provides the same level of security as on-premise data centers, there may be regulations that limit public cloud usage for certain applications.
Public Cloud vs Private Cloud vs Hybrid Cloud
With public cloud becoming more mainstream in the early part of the last decade, many established Enterprises jumped to a “cloud first” mentality for all greenfield development, primarily to save data center OPEX and CAPEX. Many others mandated that all data centers be evacuated and workloads be moved to the cloud. If you are a business that has a relatively large footprint (2000+ VM’s in my opinion); you could make the case that it may be cost advantageous to run your own data center either in a co-lo or at a hosted data center.
Today, I have far fewer conversations with C-levels around cost-only advantages of public cloud. Many businesses that mandated data center evacuation are repatriating workloads onto on-premises data centers because of ballooning public-cloud costs. Whatever be the case, it’s fair to say that public cloud was not the cost panacea that businesses sought.
Read about the savings realized by “Fat Tire” brewing company.
In all fairness to public cloud providers, they have continuously innovated to support flexible hybrid architectures. For instance, the ability to offload storage onto S3 with on-premises storage gateways. Or the Netflix use case where they are largely deployed on AWS, but they use their own CDN to distribute content across the globe.
“What is the right approach?”
There are no right or wrong answers, it really depends on your own Cloud Strategy. One could argue that with an ideal and evolving design (fully server-less, service oriented architecture e.g. A CLOUD GURU), you could run your public cloud operations on a shoestring budget. But, many CxO’S are coming to the conclusion that a hybrid approach is the best option.
Assuming that we can transform the operating model of private data centers to look very similar to that of public cloud- we can run private data centers with the same flexibility, agility and resiliency as public cloud.
Summary
Hybrid cloud provides businesses the most flexible options to support business innovation, while also keeping operational expenses and capital expenses in control. In addition, hybrid cloud with the VMware solution stack running in public cloud, provides on-demand capacity or DR capability and adds a level of resiliency without the budgetary considerations normally required to support such a solution.
Thank you Prabhu Barathi for providing me excellent feedback. (Twitter: @prabhu_b)








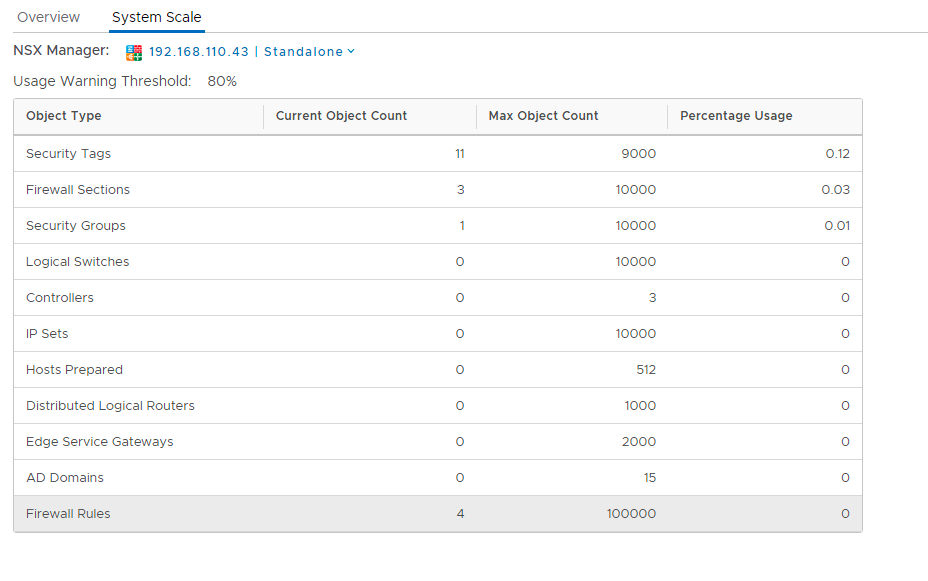
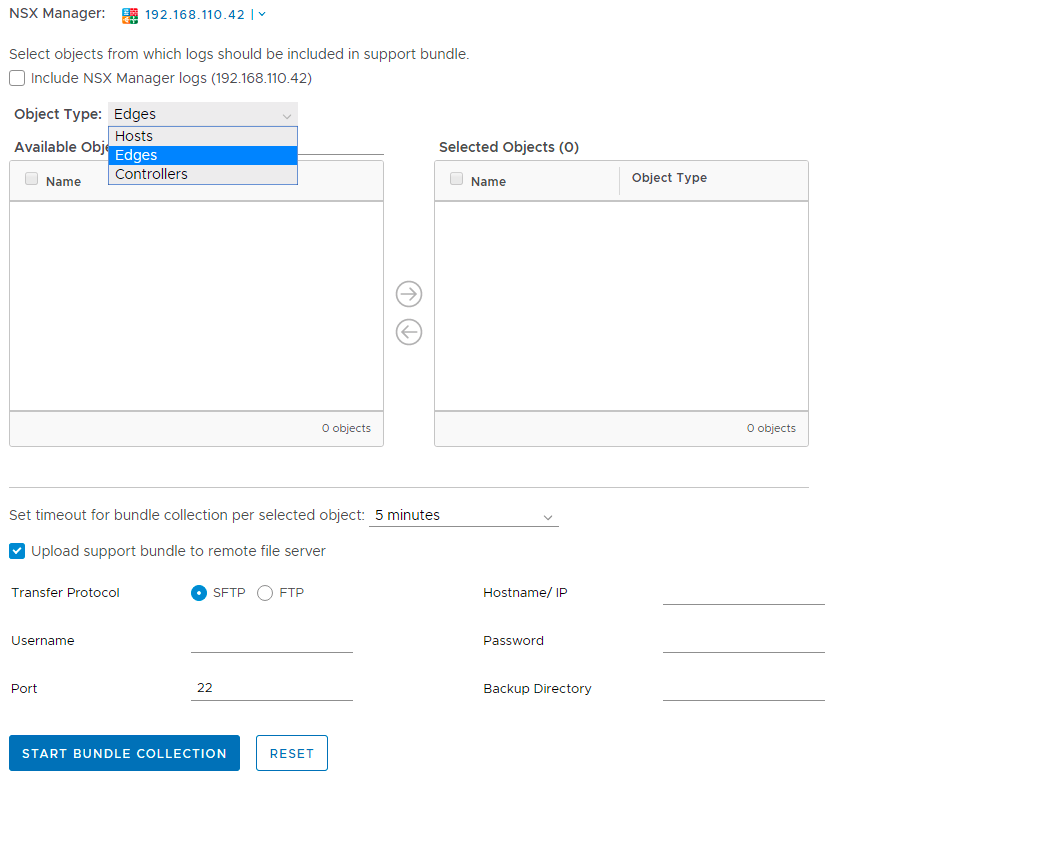 NSX Dashboard – improvements
NSX Dashboard – improvements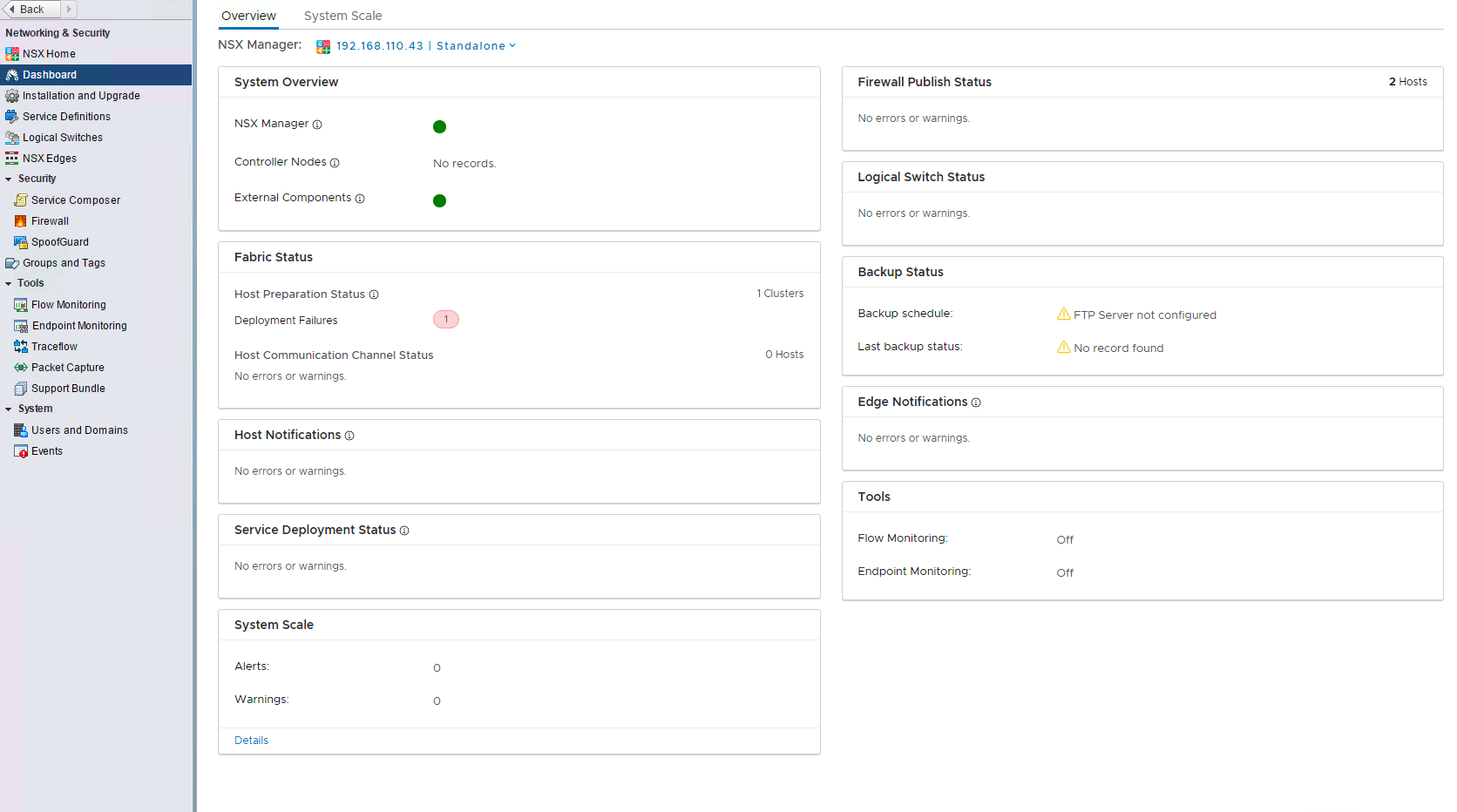
 Other Blogs related to this topic:
Other Blogs related to this topic: